How To Read Hdfs File In Pyspark
How To Read Hdfs File In Pyspark - Web spark can (and should) read whole directories, if possible. Import os os.environ [hadoop_user_name] = hdfs os.environ [python_version] = 3.5.2. Get a sneak preview here! This video shows you how to read hdfs (hadoop distributed file system) using spark. (namenodehost is your localhost if hdfs is located in local environment). Playing a file in hdfs with pyspark. How to read a csv file from hdfs using pyspark? Reading is just as easy as writing with the sparksession.read… Steps to set up an environment: Some exciting updates to our community!
Web 1 answer sorted by: Web spark can (and should) read whole directories, if possible. Reading is just as easy as writing with the sparksession.read… Playing a file in hdfs with pyspark. Web how to read a file from hdfs? Web # read from hdfs df_load = sparksession.read.csv('hdfs://cluster/user/hdfs/test/example.csv') df_load.show() how to use on data fabric? In order to run any pyspark job on data fabric, you must package your python source file into a zip file. Web 1.7k views 7 months ago. Write and read parquet files in spark/scala. Spark provides several ways to read.txt files, for example, sparkcontext.textfile () and sparkcontext.wholetextfiles () methods to read into rdd and spark.read.text () and spark.read.textfile () methods to read.
How can i read part_m_0000. The parquet file destination is a local folder. Using spark.read.json (path) or spark.read.format (json).load (path) you can read a json file into a spark dataframe, these methods take a hdfs path as an argument. (namenodehost is your localhost if hdfs is located in local environment). Reading csv file using pyspark: Add the following code snippet to make it work from a jupyter notebook app in saagie: Before reading the hdfs data, the hive metastore server has to be started as shown in. How can i find path of file in hdfs. Web table of contents recipe objective: In this page, i am going to demonstrate how to write and read parquet files in hdfs…
Reading HDFS files from JAVA program
How can i read part_m_0000. From pyarrow import hdfs fs = hdfs.connect(host, port) fs.delete(some_path, recursive=true) The parquet file destination is a local folder. Web filesystem fs = filesystem. Read from hdfs # read from hdfs df_load = sparksession.read.csv ('hdfs://cluster/user/hdfs…

DBA2BigData Anatomy of File Read in HDFS
Web # read from hdfs df_load = sparksession.read.csv('hdfs://cluster/user/hdfs/test/example.csv') df_load.show() how to use on data fabric? Web in this spark tutorial, you will learn how to read a text file from local & hadoop hdfs into rdd and dataframe using scala examples. Playing a file in hdfs with pyspark. Web how to read and write files from hdfs with pyspark. In.

Anatomy of File Read and Write in HDFS
How can i find path of file in hdfs. Web how to read and write files from hdfs with pyspark. How to read a csv file from hdfs using pyspark? Spark provides several ways to read.txt files, for example, sparkcontext.textfile () and sparkcontext.wholetextfiles () methods to read into rdd and spark.read.text () and spark.read.textfile () methods to read. Import os.

Using FileSystem API to read and write data to HDFS
Good news the example.csv file is present. From pyarrow import hdfs fs = hdfs.connect(host, port) fs.delete(some_path, recursive=true) Web how to write and read data from hdfs using pyspark | pyspark tutorial dwbiadda videos 14.2k subscribers 6k views 3 years ago pyspark tutorial for beginners welcome to dwbiadda's pyspark. Web filesystem fs = filesystem. (namenodehost is your localhost if hdfs is.

How to read CSV files using PySpark » Programming Funda
Code example this code only shows the first 20 records of the file. Write and read parquet files in spark/scala. Web 1 answer sorted by: In this page, i am going to demonstrate how to write and read parquet files in hdfs… To do this in the ambari console, select the “files view” (matrix icon at the top right).
什么是HDFS立地货
Code example this code only shows the first 20 records of the file. Get a sneak preview here! From pyarrow import hdfs fs = hdfs.connect(host, port) fs.delete(some_path, recursive=true) This video shows you how to read hdfs (hadoop distributed file system) using spark. Before reading the hdfs data, the hive metastore server has to be started as shown in.

How to read json file in pyspark? Projectpro
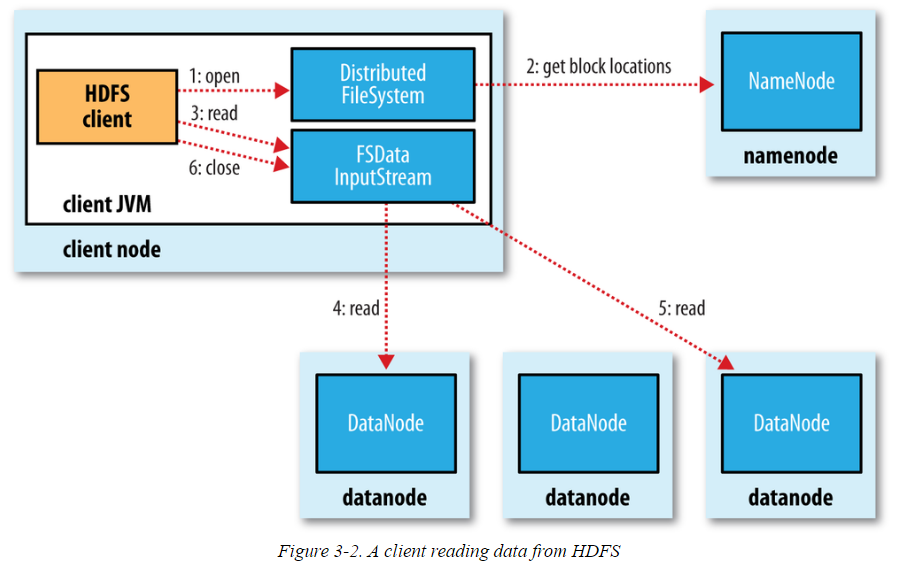
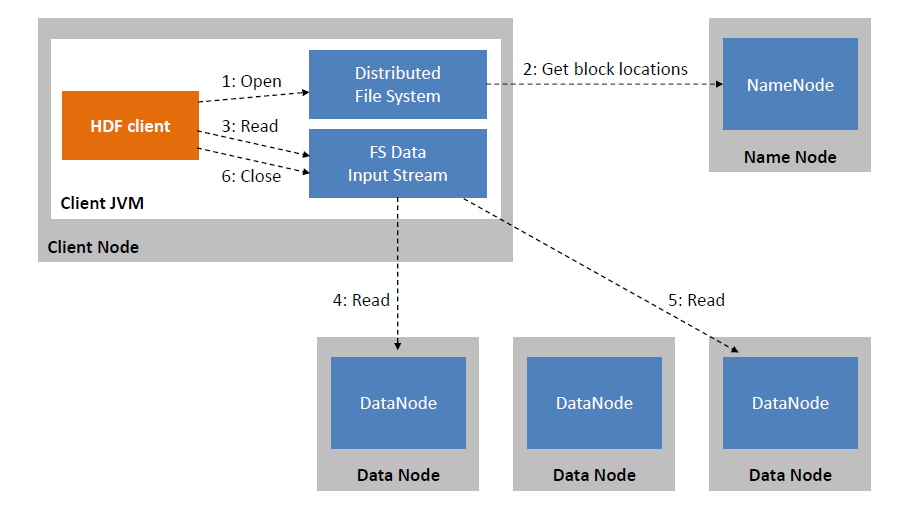
Web # read from hdfs df_load = sparksession.read.csv('hdfs://cluster/user/hdfs/test/example.csv') df_load.show() how to use on data fabric? Web the input stream will access data node 1 to read relevant information from the block located there. Write and read parquet files in spark/scala. How can i find path of file in hdfs. Web filesystem fs = filesystem.

How to read json file in pyspark? Projectpro
Web let’s check that the file has been written correctly. Similarly, it will also access data node 3 to read the relevant data present in that node. (namenodehost is your localhost if hdfs is located in local environment). Get a sneak preview here! Web write & read json file from hdfs.

Hadoop Distributed File System Apache Hadoop HDFS Architecture Edureka
Web filesystem fs = filesystem. Web in my previous post, i demonstrated how to write and read parquet files in spark/scala. Set up the environment variables for pyspark… Web the input stream will access data node 1 to read relevant information from the block located there. Spark provides several ways to read.txt files, for example, sparkcontext.textfile () and sparkcontext.wholetextfiles ().

How to read an ORC file using PySpark
Web reading a file in hdfs from pyspark 50,701 solution 1 you could access hdfs files via full path if no configuration provided. Using spark.read.json (path) or spark.read.format (json).load (path) you can read a json file into a spark dataframe, these methods take a hdfs path as an argument. Web how to read a file from hdfs? How to read.
Reading Is Just As Easy As Writing With The Sparksession.read…
Import os os.environ [hadoop_user_name] = hdfs os.environ [python_version] = 3.5.2. Web 1 answer sorted by: Steps to set up an environment: Web from hdfs3 import hdfilesystem hdfs = hdfilesystem(host=host, port=port) hdfilesystem.rm(some_path) apache arrow python bindings are the latest option (and that often is already available on spark cluster, as it is required for pandas_udf):
Write And Read Parquet Files In Spark/Scala.
Web how to write and read data from hdfs using pyspark | pyspark tutorial dwbiadda videos 14.2k subscribers 6k views 3 years ago pyspark tutorial for beginners welcome to dwbiadda's pyspark. Some exciting updates to our community! Good news the example.csv file is present. Web # read from hdfs df_load = sparksession.read.csv('hdfs://cluster/user/hdfs/test/example.csv') df_load.show() how to use on data fabric?
Reading Csv File Using Pyspark:
Web filesystem fs = filesystem. Navigate to / user / hdfs as below: How can i read part_m_0000. (namenodehost is your localhost if hdfs is located in local environment).
Get A Sneak Preview Here!
The path is /user/root/etl_project, as you've shown, and i'm sure is also in your sqoop command. Web table of contents recipe objective: In order to run any pyspark job on data fabric, you must package your python source file into a zip file. How to read a csv file from hdfs using pyspark?