Read Large Parquet File Python
Read Large Parquet File Python - My memory do not support default reading with fastparquet in python, so i do not know what i should do to lower the memory usage of the reading. Import pyarrow as pa import pyarrow.parquet as. Additionally, we will look at these file. Import pyarrow.parquet as pq pq_file = pq.parquetfile(filename.parquet) n_groups = pq_file.num_row_groups for grp_idx in range(n_groups): Columnslist, default=none if not none, only these columns will be read from the file. Only these row groups will be read from the file. If you have python installed, then you’ll see the version number displayed below the command. Web below you can see an output of the script that shows memory usage. This function writes the dataframe as a parquet file. Import dask.dataframe as dd from dask import delayed from fastparquet import parquetfile import glob files = glob.glob('data/*.parquet') @delayed def.
Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. This article explores four alternatives to the csv file format for handling large datasets: Web the parquet file is quite large (6m rows). My memory do not support default reading with fastparquet in python, so i do not know what i should do to lower the memory usage of the reading. So read it using dask. This function writes the dataframe as a parquet file. You can choose different parquet backends, and have the option of compression. Import pyarrow as pa import pyarrow.parquet as. Import pandas as pd df = pd.read_parquet('path/to/the/parquet/files/directory') it concats everything into a single dataframe so you can convert it to a csv right after: Pandas, fastparquet, pyarrow, and pyspark.
Web import dask.dataframe as dd import pandas as pd import numpy as np import torch from torch.utils.data import tensordataset, dataloader, iterabledataset, dataset # breakdown file raw_ddf = dd.read_parquet(data.parquet) # read huge file. So read it using dask. Reading parquet and memory mapping ¶ because parquet data needs to be decoded from the parquet. Web write a dataframe to the binary parquet format. If not none, only these columns will be read from the file. Web configuration parquet is a columnar format that is supported by many other data processing systems. Import pandas as pd df = pd.read_parquet('path/to/the/parquet/files/directory') it concats everything into a single dataframe so you can convert it to a csv right after: My memory do not support default reading with fastparquet in python, so i do not know what i should do to lower the memory usage of the reading. Web i'm reading a larger number (100s to 1000s) of parquet files into a single dask dataframe (single machine, all local). I have also installed the pyarrow and fastparquet libraries which the read_parquet.

Understand predicate pushdown on row group level in Parquet with
You can choose different parquet backends, and have the option of compression. The task is, to upload about 120,000 of parquet files which is total of 20gb size in overall. Web i encountered a problem with runtime from my code. I'm using dask and batch load concept to do parallelism. Web configuration parquet is a columnar format that is supported.

kn_example_python_read_parquet_file_2021 — NodePit
Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. This function writes the dataframe as a parquet file. Web import pandas as pd #import the pandas library parquet_file = 'location\to\file\example_pa.parquet' pd.read_parquet (parquet_file, engine='pyarrow') this is what the output. The task is, to upload about 120,000 of parquet files which is total of.
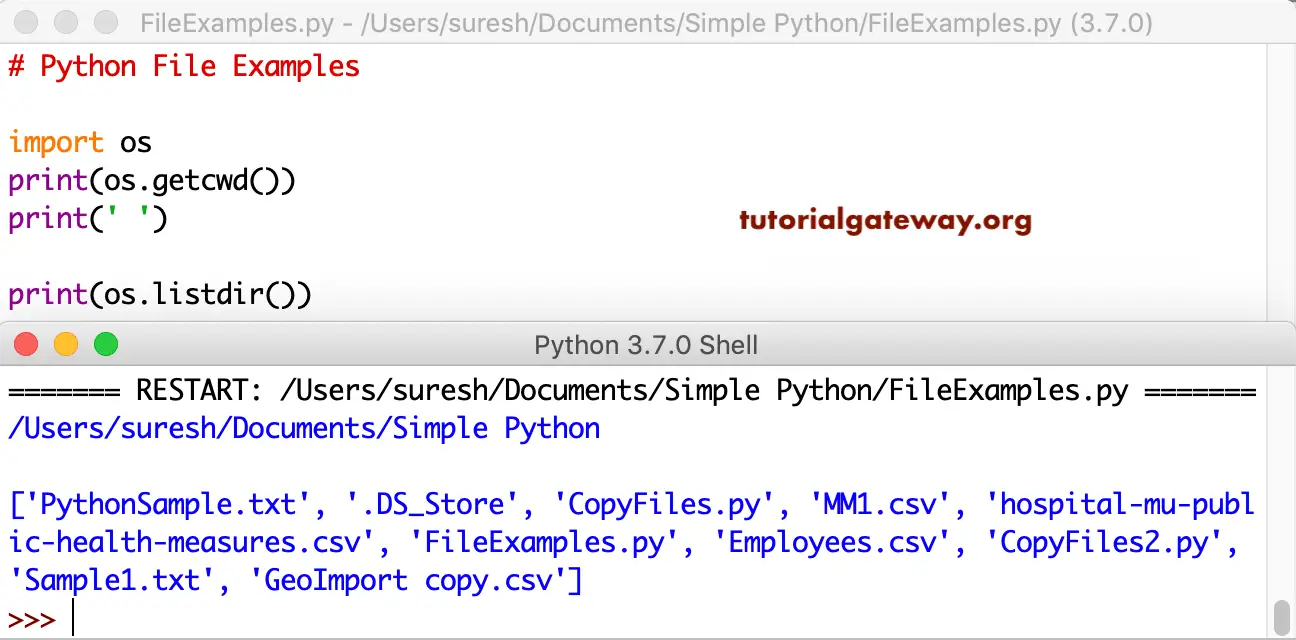
Python File Handling
Import pyarrow.parquet as pq pq_file = pq.parquetfile(filename.parquet) n_groups = pq_file.num_row_groups for grp_idx in range(n_groups): Only read the columns required for your analysis; Web how to read a 30g parquet file by python ask question asked 1 year, 11 months ago modified 1 year, 11 months ago viewed 530 times 1 i am trying to read data from a large parquet.

Python Read A File Line By Line Example Python Guides
Import pyarrow as pa import pyarrow.parquet as. This article explores four alternatives to the csv file format for handling large datasets: In our scenario, we can translate. If you have python installed, then you’ll see the version number displayed below the command. Web read streaming batches from a parquet file.

How to Read PDF or specific Page of a PDF file using Python Code by
Parameters path str, path object, file. Web so you can read multiple parquet files like this: Web to check your python version, open a terminal or command prompt and run the following command: Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. This article explores four alternatives to the csv file format.
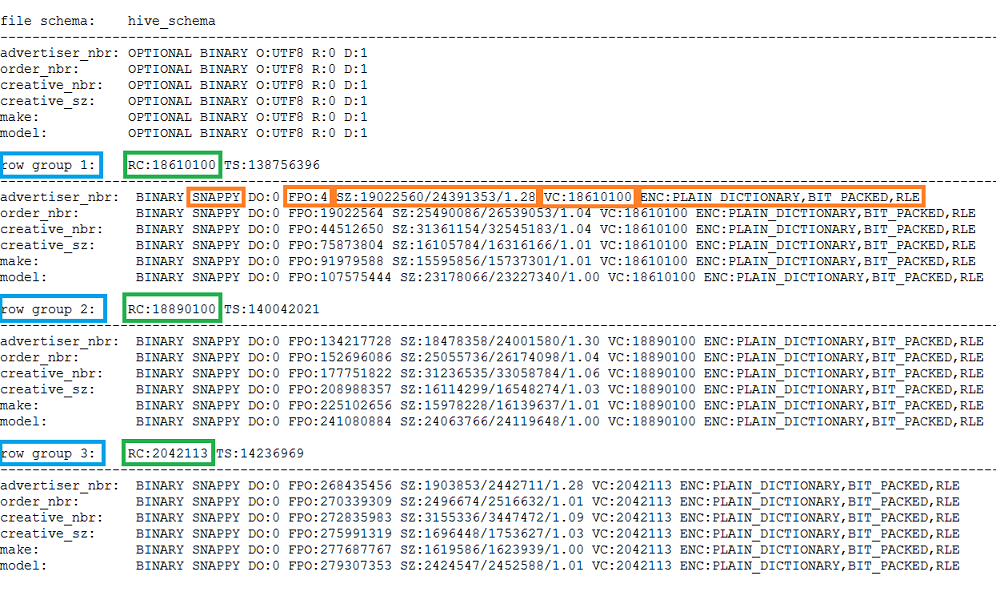
Big Data Made Easy Parquet tools utility
This function writes the dataframe as a parquet file. I found some solutions to read it, but it's taking almost 1hour. Import pyarrow as pa import pyarrow.parquet as. Web the default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable. Web below you can see an output of the script that shows memory usage.
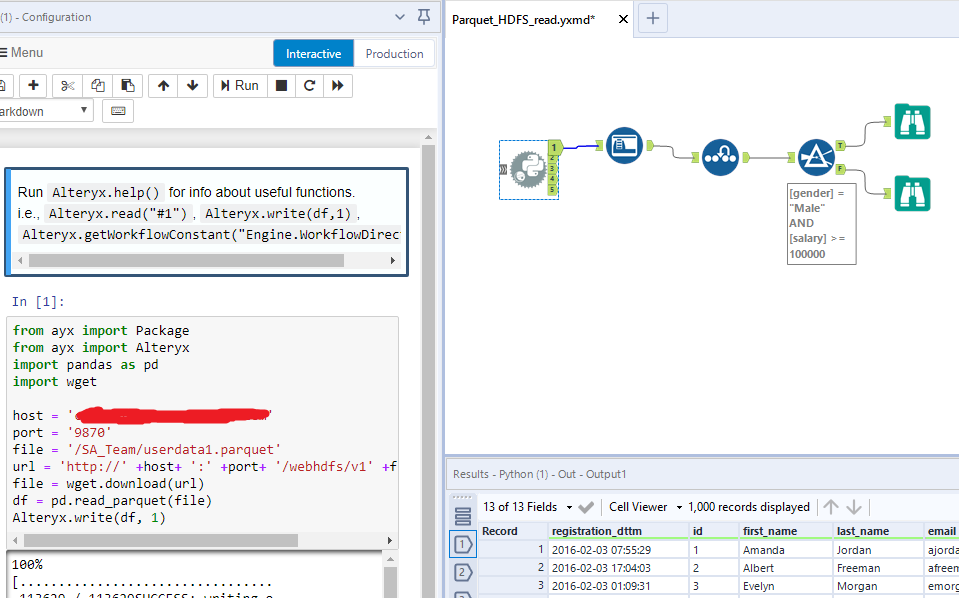
Parquet, will it Alteryx? Alteryx Community
Below is the script that works but too slow. My memory do not support default reading with fastparquet in python, so i do not know what i should do to lower the memory usage of the reading. Web in general, a python file object will have the worst read performance, while a string file path or an instance of nativefile.

python Using Pyarrow to read parquet files written by Spark increases
You can choose different parquet backends, and have the option of compression. The task is, to upload about 120,000 of parquet files which is total of 20gb size in overall. Batches may be smaller if there aren’t enough rows in the file. Web read streaming batches from a parquet file. Maximum number of records to yield per batch.

How to resolve Parquet File issue
Only these row groups will be read from the file. Only read the columns required for your analysis; Pandas, fastparquet, pyarrow, and pyspark. I have also installed the pyarrow and fastparquet libraries which the read_parquet. Maximum number of records to yield per batch.

python How to read parquet files directly from azure datalake without
In our scenario, we can translate. Web i encountered a problem with runtime from my code. Columnslist, default=none if not none, only these columns will be read from the file. Web in this article, i will demonstrate how to write data to parquet files in python using four different libraries: In particular, you will learn how to:
Additionally, We Will Look At These File.
This function writes the dataframe as a parquet file. If not none, only these columns will be read from the file. Web pd.read_parquet (chunks_*, engine=fastparquet) or if you want to read specific chunks you can try: Import pyarrow.parquet as pq pq_file = pq.parquetfile(filename.parquet) n_groups = pq_file.num_row_groups for grp_idx in range(n_groups):
Batches May Be Smaller If There Aren’t Enough Rows In The File.
Reading parquet and memory mapping ¶ because parquet data needs to be decoded from the parquet. My memory do not support default reading with fastparquet in python, so i do not know what i should do to lower the memory usage of the reading. It is also making three sizes of. Parameters path str, path object, file.
Only These Row Groups Will Be Read From The File.
Web import dask.dataframe as dd import pandas as pd import numpy as np import torch from torch.utils.data import tensordataset, dataloader, iterabledataset, dataset # breakdown file raw_ddf = dd.read_parquet(data.parquet) # read huge file. Web to check your python version, open a terminal or command prompt and run the following command: Web the csv file format takes a long time to write and read large datasets and also does not remember a column’s data type unless explicitly told. See the user guide for more details.
Web Import Pandas As Pd #Import The Pandas Library Parquet_File = 'Location\To\File\Example_Pa.parquet' Pd.read_Parquet (Parquet_File, Engine='Pyarrow') This Is What The Output.
Web so you can read multiple parquet files like this: I'm using dask and batch load concept to do parallelism. Import pyarrow as pa import pyarrow.parquet as. I have also installed the pyarrow and fastparquet libraries which the read_parquet.